C++ API¶
The C++ API of bob.learn.libsvm allows users to leverage from automatic converters for classes in bob.learn.libsvm. To use the C API, clients should first, include the header file <bob.learn.libsvm/api.h> on their compilation units and then, make sure to call once import_bob_learn_libsvm() at their module instantiation, as explained at the Python manual.
Here is a dummy C example showing how to include the header and where to call the import function:
#include <bob.blitz/capi.h>
#include <bob.io/api.h>
#include <bob.learn.libsvm/api.h>
PyMODINIT_FUNC initclient(void) {
PyObject* m Py_InitModule("client", ClientMethods);
if (!m) return 0;
if (import_bob_blitz() < 0) return 0;
if (import_bob_io() < 0) return 0;
if (import_bob_learn_libsvm() < 0) return 0;
return m;
}
Note
The include directory can be discovered using bob.learn.libsvm.get_include().
File Interface¶
- type PyBobLearnLibsvmFileObject¶
The pythonic object representation for a bob::learn::libsvm::File object.
typedef struct { PyObject_HEAD bob::learn::libsvm::File* cxx; } PyBobLearnLibsvmFileObject
- bob::learn::libsvm::File* cxx¶
A pointer to the C++ file implementation.
- int PyBobLearnLibsvmFile_Check(PyObject* o)¶
Checks if the input object o is a PyBobLearnLibsvmFileObject. Returns 1 if it is, and 0 otherwise.
Machine Interface¶
- type PyBobLearnLibsvmMachineObject¶
The pythonic object representation for a bob::learn::libsvm::Machine object.
typedef struct { PyObject_HEAD bob::learn::libsvm::Machine* cxx; } PyBobLearnLibsvmMachineObject
- bob::learn::libsvm::Machine* cxx¶
A pointer to the C++ machine implementation.
- int PyBobLearnLibsvmMachine_Check(PyObject* o)¶
Checks if the input object o is a PyBobLearnLibsvmMachineObject. Returns 1 if it is, and 0 otherwise.
- PyObject* PyBobLearnLibsvmMachine_NewFromMachine(bob::learn::libsvm::Machine* m)¶
Builds a new Python object from an existing Machine. The machine object m is stolen from the user, which should not delete it anymore.
Trainer Interface¶
- type PyBobLearnLibsvmTrainerObject¶
The pythonic object representation for a bob::learn::libsvm::Trainer object.
typedef struct { PyObject_HEAD bob::learn::libsvm::Trainer* cxx; } PyBobLearnLibsvmTrainerObject
- bob::learn::libsvm::Trainer* cxx¶
A pointer to the C++ trainer implementation.
- int PyBobLearnLibsvmTrainer_Check(PyObject* o)¶
Checks if the input object o is a PyBobLearnLibsvmTrainerObject. Returns 1 if it is, and 0 otherwise.
Other Utilities¶
- PyObject* PyBobLearnLibsvm_MachineTypeAsString(bob::learn::libsvm::machine_t s)¶
Returns a Python string representing given a machine type. Returns NULL and sets an RuntimeError if the enumeration provided is not supported.
This function will return a proper PyStringObject on Python 2.x and a PyUnicodeObject on Python 3.x.
- bob::learn::libsvm::machine_t PyBobLearnLibsvm_StringAsMachineType(PyObject* o)¶
Decodes the machine type enumeration from a pythonic string. Works with any string type or subtype. A RuntimeError is set if the string cannot be encoded as one of the available enumerations. You must check for PyErr_Occurred() after a call to this function to make sure that the conversion was correctly performed.
- bob::learn::libsvm::machine_t PyBobLearnLibsvm_CStringAsMachineType(const char* s)¶
This function works the same as PyBobLearnLibsvm_StringAsMachineType(), but accepts a C-style string instead of a Python object as input. A RuntimeError is set if the string cannot be encoded as one of the available enumerations. You must check for PyErr_Occurred() after a call to this function to make sure that the conversion was correctly performed.
- PyObject* PyBobLearnLibsvm_KernelTypeAsString(bob::learn::libsvm::kernel_t s)¶
Returns a Python string representing given a kernel type. Returns NULL and sets an RuntimeError if the enumeration provided is not supported.
This function will return a proper PyStringObject on Python 2.x and a PyUnicodeObject on Python 3.x.
- bob::learn::libsvm::kernel_t PyBobLearnLibsvm_StringAsKernelType(PyObject* o)¶
Decodes the kernel type enumeration from a pythonic string. Works with any string type or subtype. A RuntimeError is set if the string cannot be encoded as one of the available enumerations. You must check for PyErr_Occurred() after a call to this function to make sure that the conversion was correctly performed.
- bob::learn::libsvm::kernel_t PyBobLearnLibsvm_CStringAsKernelType(const char* s)¶
This function works the same as PyBobLearnLibsvm_StringAsKernelType(), but accepts a C-style string instead of a Python object as input. A RuntimeError is set if the string cannot be encoded as one of the available enumerations. You must check for PyErr_Occurred() after a call to this function to make sure that the conversion was correctly performed.
Pure C/C++ API¶
As explained above, each PyObject produced by this library contains a pointer to a pure C++ implementation of a similar object. The C++ of such objects is described in this section.
- type bob::learn::libsvm::machine_t¶
Enumeration defining the types of SVM’s available within this implementation. The following are legal values:
- C_SVC
- NU_SVC
- ONE_CLASS - currently, unsupported
- EPSILON_SVR - currently, unsupported
- NU_SVR - currently, unsupported
- type bob::learn::libsvm::kernel_t¶
Enumeration defining the types of kernels available within this implementation. The following are legal values:
- LINEAR
- POLY
- RBF
- SIGMOID
- PRECOMPUTED - currently, unsupported
- class bob::learn::libsvm::File¶
Loads a given libsvm data file. The data file format, as defined on the library README is like this:
[label] [index1]:[value1] [index2]:[value2] ... [label] [index1]:[value1] [index2]:[value2] ... [label] [index1]:[value1] [index2]:[value2] ...
The labels are integer values, so are the indexes, starting from “1” (and not from zero as a C-programmer would expect. The values are floating point.
Zero values are suppressed - this is a sparse format.
- File(const std::string& filename)¶
Constructor, initializes the file readout.
- virtual ~File()¶
Virtualized destructor
- size_t shape()¶
Returns the size of each entry in the file, in number of floats
- size_t samples()¶
Returns the number of samples in the file.
- void reset()¶
Resets the file, going back to the beginning.
- bool read(int& label, blitz::Array<double, 1>& values)¶
Reads the next entry. Values are organized according to the indexed labels at the file. Returns ‘false’ if the file is over or something goes wrong.
- bool read_(int& label, blitz::Array<double, 1>& values)¶
Reads the next entry on the file, but without checking. Returns ‘false’ if the file is over or something goes wrong reading the file.
- const std::string& filename()¶
Returns the name of the file being read.
- bool good()¶
Tests if the file is still good to go.
- bool eof()¶
- bool fail()¶
- class bob::learn::libsvm::Machine¶
Interface to svm_model, from LIBSVM. Incorporates prediction.
- Machine(const std::string& model_file)¶
Builds a new Support Vector Machine from a LIBSVM model file.
When you load using the libsvm model loader, note that the scaling parameters will be set to defaults (subtraction of 0.0 and division by 1.0). If you need scaling to be applied, set it individually using the appropriate methods bellow.
- Machine(bob::io::HDF5File& config)¶
Builds a new Support Vector Machine from an HDF5 file containing the configuration for this machine. Scaling parameters are also loaded from the file. Using this constructor assures a 100% state recovery from previous sessions.
Builds a new SVM model from a trained model. Scaling parameters will be neutral (subtraction := 0.0, division := 1.0).
Note
This method is typically only used by the respective :cpp:class`bob::learn::libsvm::Trainer` as it requires the creation of the object svm_model. You can still make use of it if you decide to implement the model instantiation yourself.
- virtual ~Machine()¶
Virtual d’tor
- size_t inputSize()¶
Tells the input size this machine expects
- size_t outputSize()¶
The number of outputs depends on the number of classes the machine has to deal with. If the problem is a regression problem, the number of outputs is fixed to 1. The same happens in a binary classification problem. Otherwise, the output size is the same as the number of classes being discriminated.
- size_t numberOfClasses()¶
Tells the number of classes the problem has.
- int classLabel(size_t i)¶
Returns the class label (as stored inside the svm_model object) for a given class ‘i’.
- bob::learn::libsvm::machine_t machineType()¶
The SVM type
- bob::learn::libsvm::kernel_t kernelType()¶
Kernel type
- int polynomialDegree()¶
Polinomial degree, if kernel is POLY
- double gamma()¶
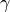 factor, for POLY, RBF or SIGMOID kernels
factor, for POLY, RBF or SIGMOID kernels
- double coefficient0()¶
Coefficient 0 for POLY and SIGMOID kernels
- bool supportsProbability()¶
Tells if this model supports probability output.
- const blitz::Array<double, 1>& getInputSubtraction()¶
Returns the input subtraction factor
- void setInputSubtraction(const blitz::Array<double, 1>& v)¶
Sets the current input subtraction factor. We will check that the number of inputs (first dimension of weights) matches the number of values currently set and will raise an exception if that is not the case.
- void setInputSubtraction(double v)¶
Sets all input subtraction values to a specific value.
- const blitz::Array<double, 1>& getInputDivision()¶
Returns the input division factor
- void setInputDivision(const blitz::Array<double, 1>& v)¶
Sets the current input division factor. We will check that the number of inputs (first dimension of weights) matches the number of values currently set and will raise an exception if that is not the case.
- void setInputDivision(double v)¶
Sets all input division values to a specific value.
- int predictClass(const blitz::Array<double, 1>& input)¶
Predict, output classes only. Note that the number of labels in the output “labels” array should be the same as the number of input.
- int predictClass_(const blitz::Array<double, 1>& input)¶
Predict, output classes only. Note that the number of labels in the output “labels” array should be the same as the number of input.
This does the same as predictClass(), but does not check the input.
- int predictClassAndScores(const blitz::Array<double, 1>& input, blitz::Array<double, 1>& scores)¶
Predicts class and scores output for each class on this SVM,
Note
The output array must be lying on contiguous memory. This is also checked.
- int predictClassAndScores_(const blitz::Array<double, 1>& input, blitz::Array<double, 1>& scores)¶
Predicts output class and scores. Same as above, but does not check
- int predictClassAndProbabilities(const blitz::Array<double, 1>& input, blitz::Array<double, 1>& probabilities)¶
Predict, output class and probabilities for each class on this SVM, but only if the model supports it. Otherwise, throws a run-time exception.
Note
The output array must be lying on contiguous memory. This is also checked.
- int predictClassAndProbabilities_(const blitz::Array<double, 1>& input, blitz::Array<double, 1>& probabilities)¶
Predicts, output class and probability, but only if the model supports it. Same as above, but does not check
- void save(const std::string& filename)¶
Saves the current model state to a file. With this variant, the model is saved on simpler libsvm model file that does not include the scaling parameters set on this machine.
- void save(bob::io::HDF5File& config)¶
Saves the whole machine into a configuration file. This allows for a single instruction parameter loading, which includes both the model and the scaling parameters.
- class bob::learn::libsvm::Trainer¶
This class emulates the behavior of the command line utility called svm-train, from LIBSVM. These bindings do not support:
- Precomputed Kernels
- Regression Problems
- Different weights for every label (-wi option in svm-train)
Fell free to implement those and remove these remarks.
Todo
Support for weight cost in multi-class classification?
- Trainer(bob::learn::libsvm::machine_t machine_type=C_SVC, bob::learn::libsvm::kernel_t kernel_type=RBF, double cache_size=100, double eps=1.e-3, bool shrinking=true, bool probability=false)¶
Builds a new trainer setting the default parameters as defined in the command line application svm-train.
- ~Trainer()¶
Destructor virtualisation
- bob::learn::libsvm::Machine* train(const std::vector<blitz::Array<double, 2>>& data)¶
Trains a new machine for multi-class classification. If the number of classes in data is 2, then the assigned labels will be -1 and +1. If the number of classes is greater than 2, labels are picked starting from 1 (i.e., 1, 2, 3, 4, etc.). If what you want is regression, the size of the input data array should be 1.
Returns a new object you must deallocate yourself.
- bob::learn::libsvm::Machine* train(const std::vector<blitz::Array<double, 2>>& data, const blitz::Array<double, 1>& input_subtract, const blitz::Array<double, 1>& input_division)¶
This version accepts scaling parameters that will be applied column-wise to the input data.
Returns a new object you must deallocate yourself.
- int getDegree()¶
- void setDegree(int v)¶
- double getGamma()¶
- void setGamma(double v)¶
- double getCoef0()¶
- void setCoef0(double v)¶
- double getCacheSizeInMb()¶
- void setCacheSizeInMb(double v)¶
- double getStopEpsilon()¶
- void setStopEpsilon(double v)¶
- double getCost()¶
- void setCost(double v)¶
- double getNu()¶
- void setNu(double v)¶
- double getLossEpsilonSVR()¶
- void setLossEpsilonSVR(double v)¶
- bool getUseShrinking()¶
- void setUseShrinking(bool v)¶
- bool getProbabilityEstimates()¶
- void setProbabilityEstimates(bool v)¶