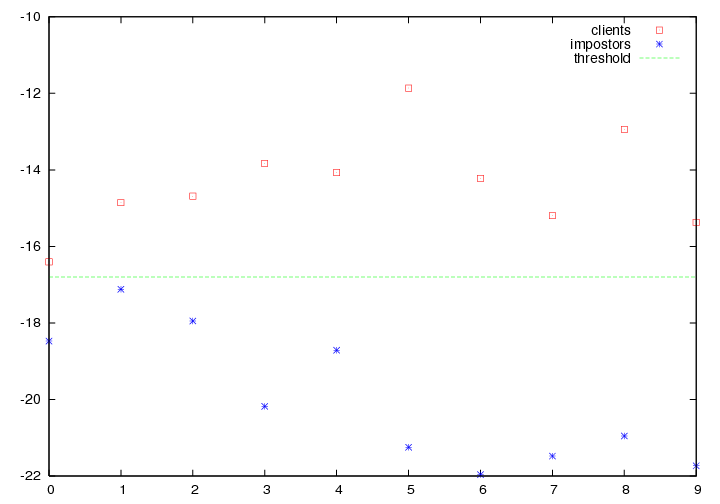
What is the structure of protocol files ?
Protocol variant
A experiment protocol should be associated to every database
(lp for XM2VTS, english for BANCA). However,
several variations could be introduced in each protocol to
observe the behaviour of the system in different conditions
(changing the distribution of train/test data). Each variation
is called a variant.
There exist 2 variants for XM2VTS (lp1 and lp2) and
7 variants for BANCA (Mc, Ua, Ud, Ma, Md, P and G).
For practical reasons, we only provide protocol files for G and P
mainly because protocol P includes Mc, Ua, Ud.
The interested reader should refer to the paper describing the
BANCA protocol.
> ls xm2vts/protocols/lp
files_real_ids.lst
lp1/
lp2/
norm/
> ls banca/protocols/english
files_real_ids.lst
G/
P/
norm/
Explaining the nomenclature of data files
The file files_real_ids.lst is database dependent. It
is interpreted by pyVerif to specify how to recover the real
id from the filename. This assume that all data files from the
database follow the same naming convention.
The files_real_ids.lst for XM2VTS is:
def id_of (filename):
"""
Specific for Xm2vts: real id corresponds the 3rd first chars of the
file name.
"""
f = filename.split("_")
real_id = f[0]
return (real_id)
The following files are from the XM2VTS database:
003_1_1.ppm means image ppm from person 003 (read id) recorded during session 1, shot 1
003_1_2.ppm means image ppm from person 003 (read id) recorded during session 1, shot 2
003_2_1.ppm means image ppm from person 003 (read id) recorded during session 2, shot 1
003_3_1.ppm means image ppm from person 003 (read id) recorded during session 3, shot 1
003_4_1.ppm means image ppm from person 003 (read id) recorded during session 4, shot 1
004_1_1.ppm means image ppm from person 003 (read id) recorded during session 1, shot 1
...
004_3_2.ppm means image ppm from person 003 (read id) recorded during session 3, shot 2
...
371_4_2.ppm means image ppm from person 371 (read id) recorded during session 4, shot 2
The files_real_ids.lst for BANCA is:
def id_of (filename):
"""
Specific for Banca: real id is the 3rd first chars of the
file name.
"""
f = filename.split("_")
gender = f[1]
if gender == 'f':
gender = "fem"
else:
gender = "mal"
real_id = f[0]
lang = f[5]
group = f[2]
return (group+"_"+gender+"_"+lang+"_"+real_id)
The following files are from the BANCA database:
1001_f_g1_s01_1001_en_1.ppm means image ppm from person 1001 (this person is a female) from group 1 recorded during session 1, shot 1
1001_f_g1_s01_1001_en_2.ppm means image ppm from person 1001 (this person is a female) from group 1 recorded during session 1, shot 2
1001_f_g1_s01_1001_en_3.ppm means image ppm from person 1001 (this person is a female) from group 1 recorded during session 1, shot 3
1001_f_g1_s01_1001_en_4.ppm means image ppm from person 1001 (this person is a female) from group 1 recorded during session 1, shot 4
1001_f_g1_s01_1001_en_5.ppm means image ppm from person 1001 (this person is a female) from group 1 recorded during session 1, shot 5
...
1001_f_g1_s04_1005_en_1.ppm means image ppm from person 1001 (this person is a female) from group 1 recorded during session 4, shot 1
...
1005_f_g1_s07_1012_en_1.ppm means image ppm from person 1005 (this person is a female) from group 1 recorded during session 7, shot 1
...
1027_m_g1_s05_1032_en_1.ppm means image ppm from person 1027 (this person is a male) from group 1 recorded during session 5, shot 1
...
9001_f_wm_s01_9001_en_1.ppm means image ppm from person 9001 (this person is a female) from world model recorded during session 1, shot 1
...
9059_f_wm_s09_9060_en_5.ppm means image ppm from person 9059 (this person is a female) from world model recorded during session 9, shot 5
Protocol dev/test files
These are the main protocol files. It indicates the files to
use to train the client models and to generate the score
files. There are 2 sets of files: the dev set and the test
set. In each set, one can find a list of files to train the
client models (for_models.lst and eventually for_models_impostors.lst)
and to compute clients/impostors scores (for_scores.lst).
Protocol dev/test files from XM2VTS:
lp1/dev:
for_models.lst
for_models_impostors.lst
for_scores.lst
lp1/test:
for_scores.lst
Protocol dev/test files from BANCA:
P/dev:
for_models.lst
for_models_impostors.lst
for_scores.lst
P/test:
for_models.lst
for_models_impostors.lst
for_scores.lst
Please note that the file for_models.lst (and therefore
for_models_impostors.lst) is optional in the test set.
In which case, we consider all the clients been the same than
in the dev set. This is the case with the XM2VTS database
where we only compute scores on the test set. On the contrary,
in the BANCA database, 2 different sets of clients are
available: one for the dev set and one for the test set. In
BANCA, the group 1 is considered as the dev set and the group
2 as the test set.
for_models.lst
This file is a table with as many keys than client identities
(003, 004, ...,). All the files associated to a given key will
be used by pyVerif to generate the list of client files to train the
corresponding client model.
003_1_1 003
003_2_1 003
003_3_1 003
004_1_1 004
004_2_1 004
004_3_1 004
...
370_1_1 370
370_2_1 370
370_3_1 370
371_1_1 371
371_2_1 371
371_3_1 371
for_models_impostors.lst (optional)
This file is a table with as many keys than client identities
(003, 004, ...,). All the files associated to a given key will
be used by pyVerif to generate the list of impostor files to train the
corresponding client model. This file is only requiered when
training models such as MLP or SVM that needs examples and
non-examples.
004_1_1 004_2_1 004_3_1 005_1_1 005_1_2 ... 371_1_1 371_2_1 371_3_1 003
003_1_1 003_2_1 003_3_1 005_1_1 005_1_2 ... 371_1_1 371_2_1 371_3_1 004
...
003_1_1 003_2_1 003_3_1 004_1_1 004_2_1 ... 370_1_1 370_2_1 370_3_1 371
for_scores.lst
This file is also very important. It indicates which file
should be used to be tested against each model. When the real
id of the file correspond to the model id this is a client
access. When the real id of the file doesn't correspond to the
model id this is a impostor access.
In the file, you can then find all client accesses:
003_1_2 003
003_2_2 003
003_3_2 003
004_1_2 004
004_2_2 004
004_3_2 004
...
370_1_2 370
370_2_2 370
370_3_2 370
371_1_2 371
371_2_2 371
371_3_2 371
and all impostor accesses:
000_1_1 003
000_1_1 004
000_1_1 005
000_1_1 006
000_1_1 009
000_1_1 012
000_1_1 013
000_1_1 016
...
000_1_1 366
000_1_1 369
000_1_1 370
000_1_1 371
000_1_2 003
...
000_1_2 371
...
331_4_2 369
331_4_2 370
331_4_2 371
Protocol norm files
The norm directory provides for each variant the list
of files to use to build the world model if any or to compute
the PCA/LDA matrix for instance. For example, here is
the file train_world_lp1.lst:
003_1_1 world
003_2_1 world
003_3_1 world
004_1_1 world
004_2_1 world
004_3_1 world
005_1_1 world
005_2_1 world
005_3_1 world
...
370_1_1 world
370_2_1 world
370_3_1 world
371_1_1 world
371_2_1 world
371_3_1 world
This file is a table with a unique key.
This file should contain at least 2 columns. The last column
should contain the same keyword "world", and all the columns
before (separated by a space) provide the basename of files to
use to build the world model.
Scores file format
A score file generated by pyVerif contains at least 4 columns.
The claim id, the real id, the basename of the claim id, the
score. The score can be as simple as a distance between
feature vectors or the output of a MLP given a feature vector,
or the likelihood of a GMM.
Scores file format of a metric or MLP-based method:
000 003 000_1_1 0.255224
000 003 000_1_2 0.304895
000 003 000_2_1 0.0760654
...
003 003 003_1_2 0.546845
003 003 003_2_2 0.643778
003 003 003_3_2 0.606807
004 004 004_1_2 0.845226
004 004 004_2_2 0.635136
004 004 004_3_2 0.53234
...
Scores file format of a GMM-based method:
000 003 000_1_1 -100.7 -100.28 -0.42
000 003 000_1_2 -100.716 -100.263 -0.453
000 003 000_2_1 -100.637 -100.052 -0.585
...
003 003 003_1_2 -102.96 -103.431 0.471
003 003 003_2_2 -101.862 -103.337 1.475
003 003 003_3_2 -101.081 -102.313 1.232
004 004 004_1_2 -99.0497 -100.13 1.0803
004 004 004_2_2 -98.9131 -99.7969 0.8838
004 004 004_3_2 -98.3267 -99.2954 0.9687
...
In the case of the GMM, we have 3 columns of scores. The first
one is the log-likelihood of the claim for the client model. The
second one is the log-likelihood of the claim for the world model.
The last column is the difference between the two.
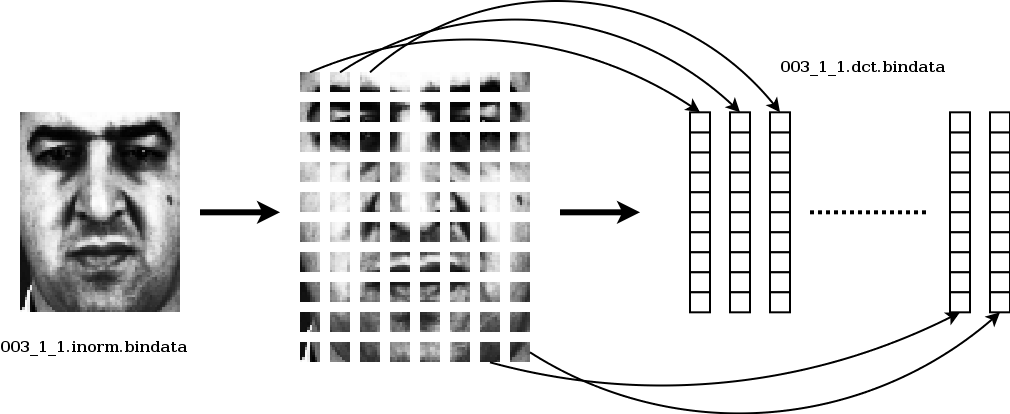
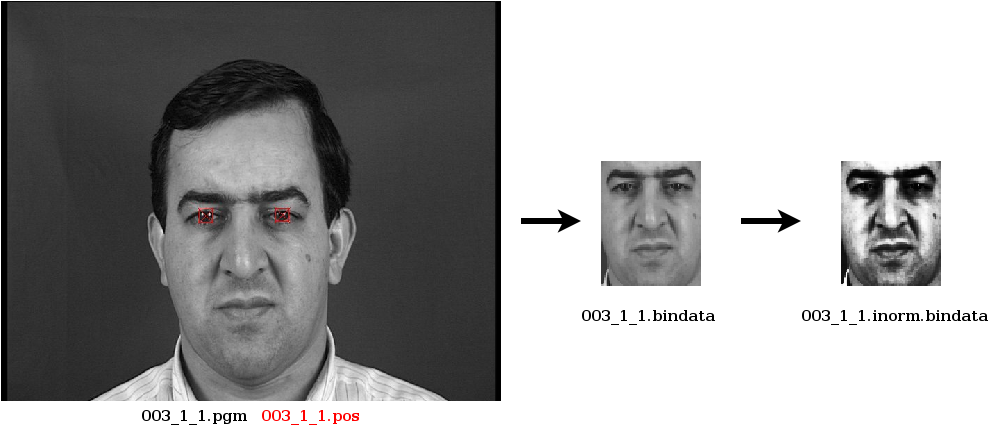 # # Extract the face from the pgm image 003_1_1.pgm according to eyecenter coordinates in the pos file 003_1_1.pos # # This program automatically performs geometric normalization such scaling and rotation compensation to align the eyes. # # Options: # -facemodel 3 : means to extract the face as a 64x80 image # -postype 1 : indicates how to read the pos file # -oneface : precises that there is only one face to extract (the pos file doen't contain the number of faces) # -norm : scales output pixel values between 0 and 1 # -savebin : saves the output face into the file 003_1_1.bindata ./bin/faceExtract 003_1_1.pgm 003_1_1.pos -facemodel 3 -postype 1 -oneface -norm -savebin 003_1_1.bindata # # Perform photometric normalization on the extracted face # # Options: # -unnorm : the input image has pixel values scaled between 0 and 1 # -mirroradd : mirrors the image and adds it into the output file # -norm : scales output pixel values between 0 and 1 # -o : saves the output face into the file 003_1_1.inorm.bindata # ./bin/binfacenormalize 003_1_1.bindata 64 80 -unnorm -mirroradd -norm -o 003_1_1.inorm.bindata
# # Extract the face from the pgm image 003_1_1.pgm according to eyecenter coordinates in the pos file 003_1_1.pos # # This program automatically performs geometric normalization such scaling and rotation compensation to align the eyes. # # Options: # -facemodel 3 : means to extract the face as a 64x80 image # -postype 1 : indicates how to read the pos file # -oneface : precises that there is only one face to extract (the pos file doen't contain the number of faces) # -norm : scales output pixel values between 0 and 1 # -savebin : saves the output face into the file 003_1_1.bindata ./bin/faceExtract 003_1_1.pgm 003_1_1.pos -facemodel 3 -postype 1 -oneface -norm -savebin 003_1_1.bindata # # Perform photometric normalization on the extracted face # # Options: # -unnorm : the input image has pixel values scaled between 0 and 1 # -mirroradd : mirrors the image and adds it into the output file # -norm : scales output pixel values between 0 and 1 # -o : saves the output face into the file 003_1_1.inorm.bindata # ./bin/binfacenormalize 003_1_1.bindata 64 80 -unnorm -mirroradd -norm -o 003_1_1.inorm.bindata