Biometric Recognition¶
This section contains information about the biometric verification dataset. For information about the presentation attack (a.k.a. spoofing) dataset, refer to Presentation Attacks.
Data¶
All fingervein samples have been recorded using the open finger vein sensor described in [BT12]. A total of 110 subjects presented their 2 indexes to the sensor in a single session and recorded 2 samples per finger with 5 minutes separation between the 2 trials. The database, therefore, contains a total of 440 samples and 220 unique fingers.
The recordings were performed at 2 different locations, always inside buildings with normal light conditions. The data for the first 78 subjects derives from the the first location while the remaining 32 come from the second location.
The dataset is composed of 40 women and 70 men whose ages are between 18 and 60 with an average at 33. Information about gender and age of subjects are provided with our dataset interface.
Samples are stored as follow with the following filename convention:
full/bf/004-F/004_L_2. The fields can be interpreted as
<size>/<source>/<subject-id>-<gender>/<subject-id>_<side>_<trial>. The
<size> represents one of two options full or cropped. The images in
the full directory contain the full image produced by the sensor. The
images in the cropped directory represent pre-cropped region-of-interests
(RoI) which can be directly used for feature extraction without
region-of-interest detection. We provide both verification and
presentation-attack detection protocols for full or cropped versions of
the images.
The <source> field may one of bf (bona fide) or pa
(presentation attack) and represent the genuiness of the image. Naturally,
biometric recognition uses only images of the bf folder for all protocols.
The <subject-id> is a 3 digits number that stands for the subject’s
unique identifier. The <gender> value can be either M (male) or
F (female). The <side> corresponds to the index finger side and can be
set to either “R” or “L” (“Right” or “Left”). The <trial> corresponds to
either the first (1) or the second (2) time the subject interacted with the
device.
Images in the full folder are stored in PNG format, with a size of 250x665
pixels (height, width). Size of the files is around 80 kbytes per sample.
Here are examples of bona fide (bf) samples from the full folder
inside the database, for subject 029-M:

Fig. 1 Image from subject 0029 (male). This image corresponds to the first
trial for the left index finger.¶

Fig. 2 Image from subject 0029 (male). This image corresponds to the second
trial for the left index finger.¶
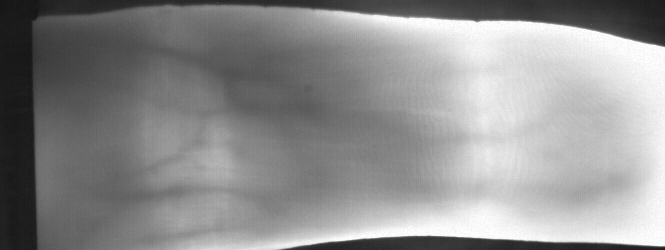
Fig. 3 Image from subject 0029 (male). This image corresponds to the first
trial for the right index finger.¶

Fig. 4 Image from subject 0029 (male). This image corresponds to the second
trial for the right index finger.¶
Images in the cropped folder are stored in PNG format, with a size of
150x565 pixels (height, width). Because of the simplified sensor design and
fixed finger positioning, cropping was performed by simply removing 50 pixels
from each border of the original raw image. Size of the files is around 40
kbytes per sample.
Here are examples of bona fide (bf) samples from the cropped folder
inside the database, for subject 029-M:

Fig. 5 Image from subject 0029 (male). This image corresponds to the first
trial for the left index finger. This version contains only the pre-cropped
region-of-interest.¶

Fig. 6 Image from subject 0029 (male). This image corresponds to the second
trial for the left index finger. This version contains only the pre-cropped
region-of-interest.¶

Fig. 7 Image from subject 0029 (male). This image corresponds to the first
trial for the right index finger. This version contains only the pre-cropped
region-of-interest.¶

Fig. 8 Image from subject 0029 (male). This image corresponds to the second
trial for the right index finger. This version contains only the pre-cropped
region-of-interest.¶
Acquisition Protocol¶
Subjects were asked to put their index in the sensor and then adjust the position such that the finger is on the center of the image. Bram Ton’s Graphical User Interface (GUI) was used for visual feedback, Near Infra Red light control and acquisition. When the automated light control was performing unproperly the operator adjusted manually the intensities of the leds to achieve a better contrast of the vein pattern.
Subjects first presented an index, then the other, a second time the first index and a second time the second index. The whole process took around 5 minutes per subject in average.
Annotations¶
We provide region-of-interest (RoI) hand-made annotations for all images in
this dataset. The annotations mark the place where the finger is on the image,
excluding the background. The annotation file is a text file with one
annotation per line in the format (y, x), respecting Bob’s image encoding
convention. The interconnection of these points in a polygon forms the RoI.
Annotations can be loaded using bob.db.verafinger.File.roi().
Protocols¶
This package comes preset with 4 distinct evaluation protocols on the VERA
fingervein database. Each protocol contains a variant with a prefixed
Cropped-, indicating they use images from the cropped folder instead of
the full folder. These 4 protocols are detailed next.
The “Nom” protocol¶
The “Nom” (normal operation mode) protocol corresponds to the standard verification scenario. For the VERA database, each finger for all subjects will be used for enrolling and probing. Data from the first trial is used for enrollment, while data from the second trial is used for probing. Matching happens exhaustively. In summary:
110 subjects x 2 fingers = 220 unique fingers
2 trials per finger, so 440 unique images
Use trial 1 for enrollment and trial 2 for probing
Total of 220 genuine scores and 220x219 = 48180 impostor scores
No images for training
Note
To access the version of the protocol using images in the cropped
folder, use the protocol name “Cropped-Nom”.
The “Fifty” protocol¶
The “Fifty” protocol is meant as a reduced version of the “Nom” protocol, for quick check purposes. All definitions are the same, except we only use the first 50 subjects in the dataset (numbered 1 until 59). In summary:
50 subjects x 2 fingers = 100 unique fingers
2 sessions per finger, so 200 unique images
Use trial sample 1 for enrollment and trial sample 2 for probing
Total of 100 genuine scores and 100x99 = 9900 impostor scores
Use all remaining images for training (440-200 = 240 images). In this case, the remaining images all belong to different subjects that those on the development set.
Note
To access the version of the protocol using images in the cropped
folder, use the protocol name “Cropped-Fifty”.
The “B” protocol¶
The “B” protocol was created to simulate an evaluation scenario similar to that from the UTFVP database (see [BT12]). 108 unique fingers were picked:
Each of the 2 fingers from the first 48 subjects (96 unique fingers), subjects numbered from 1 until 57
The left fingers from the next 6 subjects (6 unique fingers), subjects numbered from 58 until 65
The right fingers from the next 6 subjects (6 unique fingers), subjects numbered from 66 until 72
Then, protocol “B” was setup in this way:
108 unique fingers
2 trials per finger, so 216 unique images
Match all fingers against all images (even against itself)
Total of 216x2 = 432 genuine scores and 216x214 = 46224 impostor scores
Use all remaining images for training (440-216 = 224 samples). In this case, the remaining images not all belong to different subjects that those on the development set.
Note
To access the version of the protocol using images in the cropped
folder, use the protocol name “Cropped-B”.
The “Full” protocol¶
The “Full” protocol is similar to protocol “B” in the sense it tries to match all existing images against all others (including itself), but uses all subjects and samples instead of a limited set. It was conceived to facilitate cross-folding tests on the database. So:
220 unique fingers
2 trials per finger, so 440 unique images
Match all fingers against all images (even against itself)
Total of 440x2 = 880 genuine scores and 440x438 = 192720 impostor scores
No samples are available for training in this protocol
Note
To access the version of the protocol using images in the cropped
folder, use the protocol name “Cropped-Full”.